
Series “AI Lab”: Epoch AI - Can AI Scaling Continue Through 2030? #5
Is it technically feasible for the current rapid pace of AI training scaling to continue through 2030?

Welcome back to the AI Lab Series, where we delve into the latest advancements shaping the world of artificial intelligence. This week, we're unpacking Epoch AI incredibly well done report about AI scalability. Can the current rapid pace of AI training scaling - approximately 4x per year - continue through 2030?
Introduction
Recent advancements in AI capabilities have been significantly driven by scaling up computational resources used in training AI models. Our research indicates that this increase in compute accounts for a substantial portion of performance improvements. The consistent gains from scaling have led AI labs to expand training compute at an approximate rate of 4x per year.
This rapid growth rate surpasses other technological expansions, such as mobile phone adoption and solar energy capacity installation. In this article, we explore whether this pace of AI training scaling can continue through 2030 by examining four key potential constraints:
Power Availability
Chip Manufacturing Capacity
Data Scarcity
The Latency Wall
We incorporate industry projections, including semiconductor manufacturing plans and electricity providers' capacity growth forecasts, to assess these constraints.
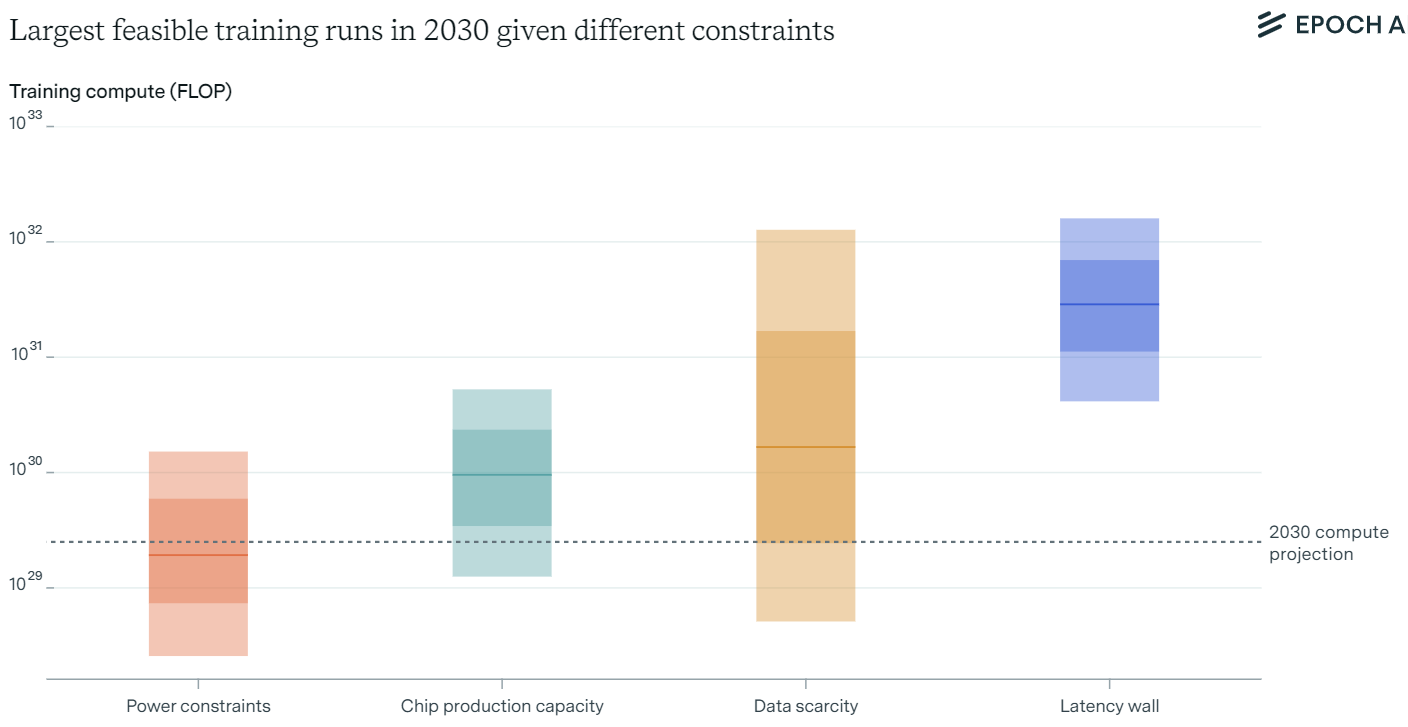
Our main finding is that training runs of up to 2×10292 \times 10^{29}2×1029 FLOP are likely feasible by 2030. This scale surpasses GPT-4 to the same extent that GPT-4 exceeded GPT-2. Such advancements could lead to AI capabilities as transformative as those seen between 2019 and 2023.
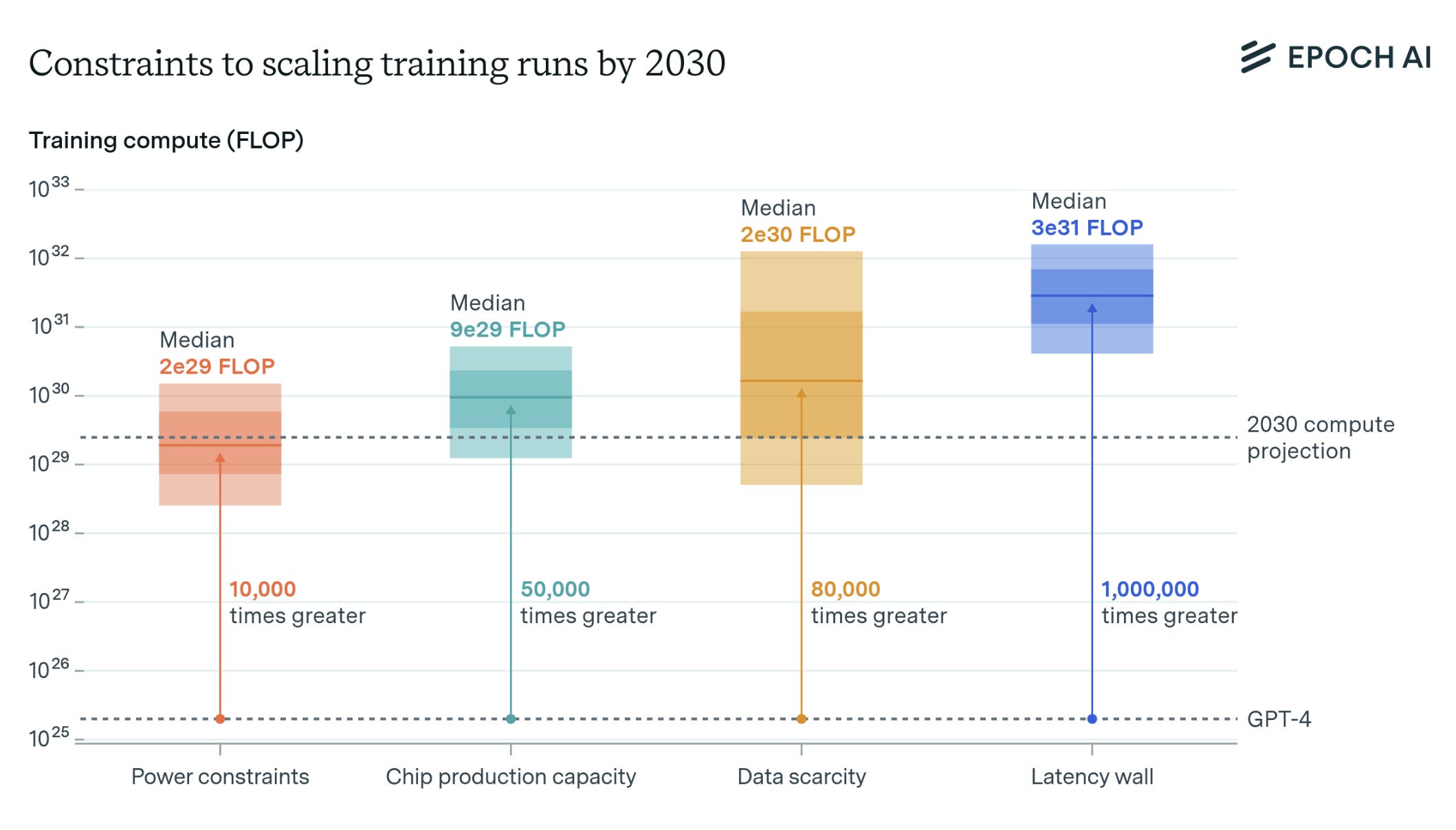
What Constrains AI Scaling This Decade
Power Constraints
The Current Trend of AI Power Demand
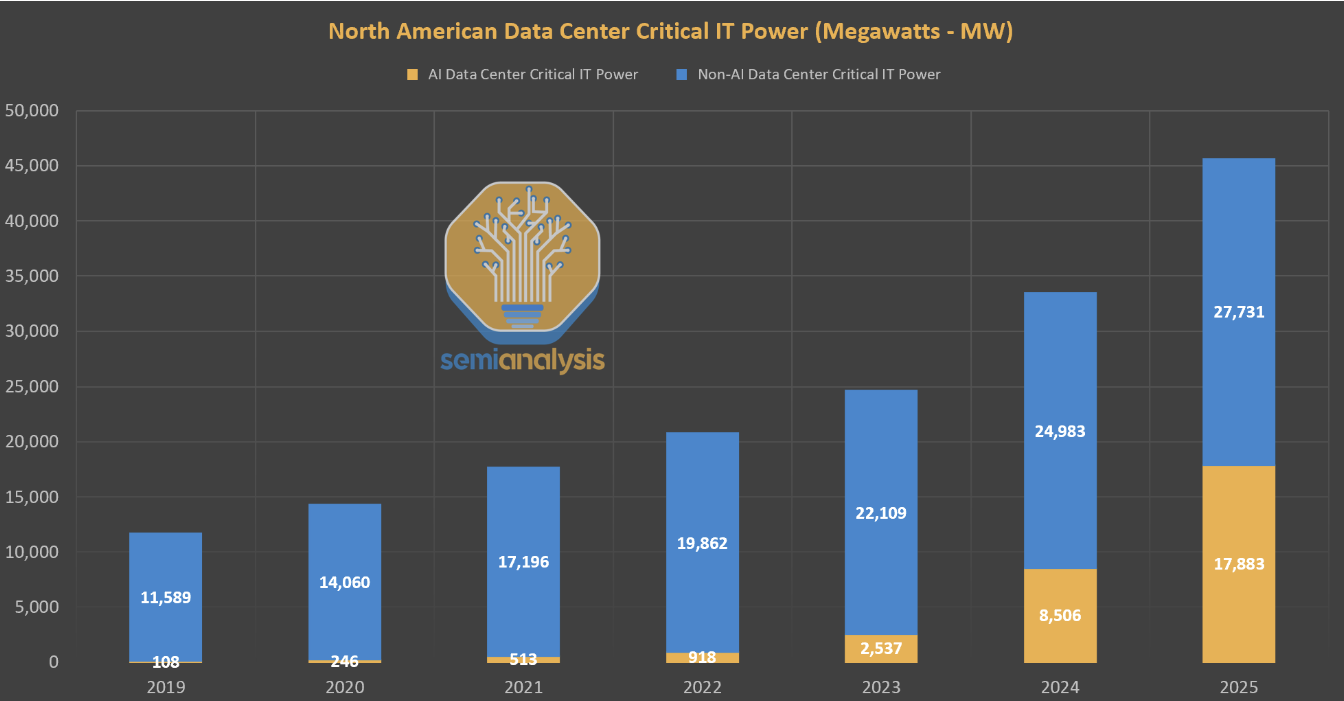
AI training currently consumes a small but rapidly growing portion of data center power usage. The state-of-the-art GPU, Nvidia's H100, has a peak power demand of approximately 1,700W per GPU when accounting for supporting hardware and overhead.
Recent models like Llama 3.1 405B used clusters requiring around 27 MW of power. Projecting forward, if training compute continues to grow at 4x per year, training runs in 2030 would require about 200 times more power than current models, estimating a demand of around 6 GW.
This power demand is significant compared to the total power consumption of all U.S. data centers today (~20 GW) but small relative to the U.S.'s total installed power capacity (~1,200 GW).
Power Constraints for Geographically Localized Training Runs
Single data center campuses between 1 to 5 GW are likely possible by 2030. Companies like Amazon and Microsoft are already planning or considering such large-scale facilities. A 5 GW data center could support training runs of up to 2×10292 \times 10^{29}2×1029 FLOP, accounting for expected advances in energy efficiency and increased training duration.
Power Constraints for Geographically Distributed Training
Distributed training across multiple data centers can tap into larger power resources. Projections suggest that U.S. data center capacity could grow to 90 GW by 2030, with a significant portion allocated to AI. Assuming a company can utilize about 26% of AI data center capacity, an 8 GW distributed training run is plausible.
Feasibility of Geographically Distributed Training
Geographically distributed training is technically feasible and already in practice. Latency and bandwidth are critical considerations but are not likely to be the binding constraints. Latency across U.S. data centers can be managed and advancements in data center switch technology suggest that sufficient bandwidth can be achieved to support large-scale distributed training.
Modeling Energy Bottlenecks
Combining these analyses, we conclude that training runs between 1×10281 \times 10^{28}1×1028 to 2×10302 \times 10^{30}2×1030 FLOP are feasible by 2030, considering both localized and distributed power constraints.
Chip Manufacturing Capacity
Current Production and Projections
AI chip production, particularly GPUs like Nvidia's H100, is crucial for scaling AI. Current production is constrained by advanced packaging processes and high-bandwidth memory (HBM) production. TSMC, Nvidia's primary chip fab, is rapidly expanding its packaging capacity, aiming for significant growth in the coming years.
Modeling GPU Production and Compute Availability
Projected growth rates for GPU production range between 30% to 100% per year. By 2030, this could result in enough GPUs to support training runs up to 9×10299 \times 10^{29}9×1029 FLOP, even after accounting for distribution among multiple labs and usage for model serving. However, uncertainties remain due to potential bottlenecks in packaging and memory production.
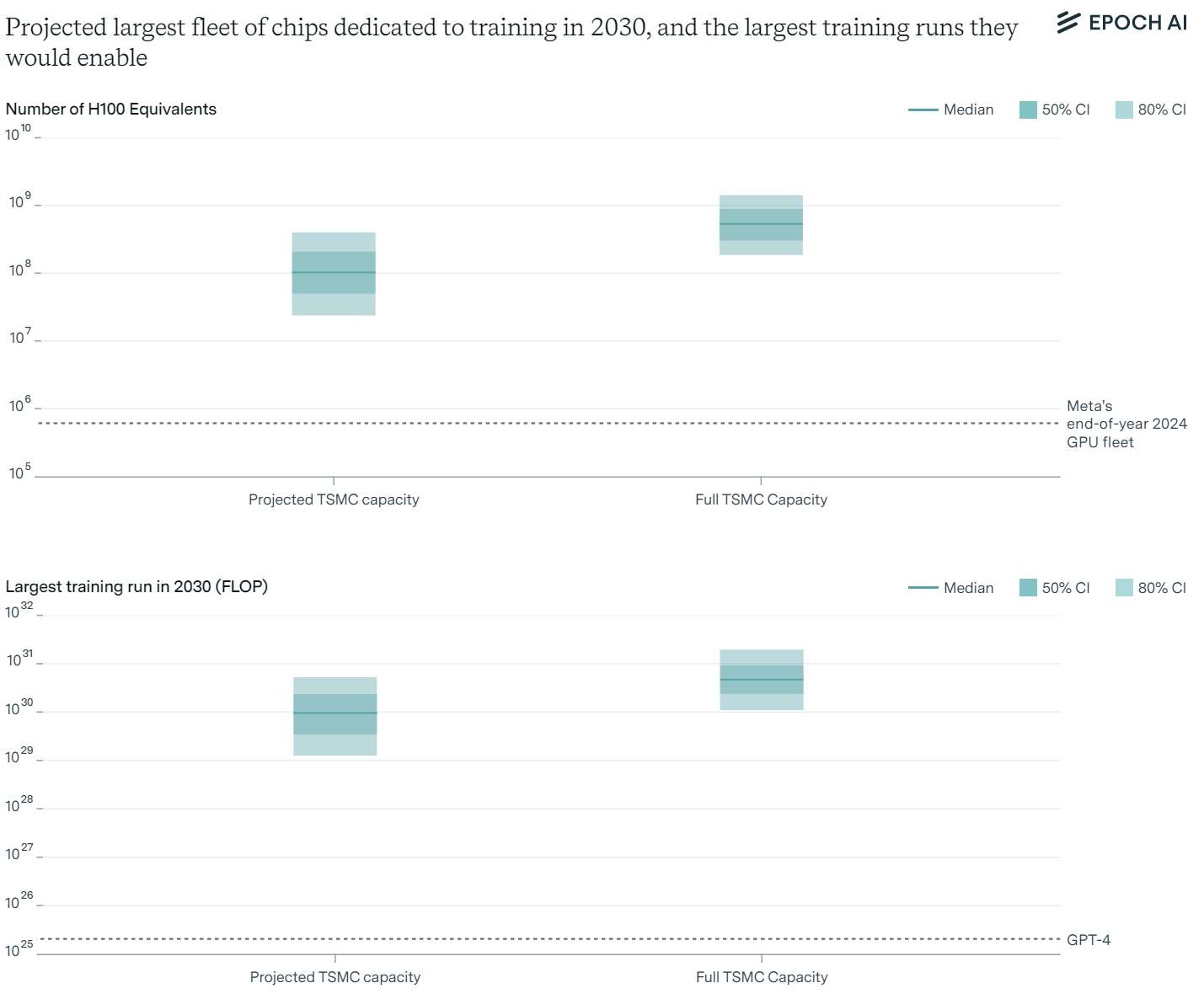
Data Scarcity
The availability of high-quality data is essential for training large AI models.
Multimodality
To mitigate data scarcity, AI labs can leverage multimodal data, including images, videos and audio. Current models already incorporate a significant portion of image data. By efficiently encoding multimodal data, the effective stock of training data could be increased substantially, allowing for training runs up to 2×10322 \times 10^{32}2×1032 FLOP.
Synthetic Data
Generating synthetic data using existing AI models is another avenue to expand training data. While promising, this approach faces challenges such as potential model collapse and computational overhead. Nonetheless, synthetic data could play a role in overcoming data bottlenecks, although our analysis conservatively excludes it due to current uncertainties.
Latency Wall
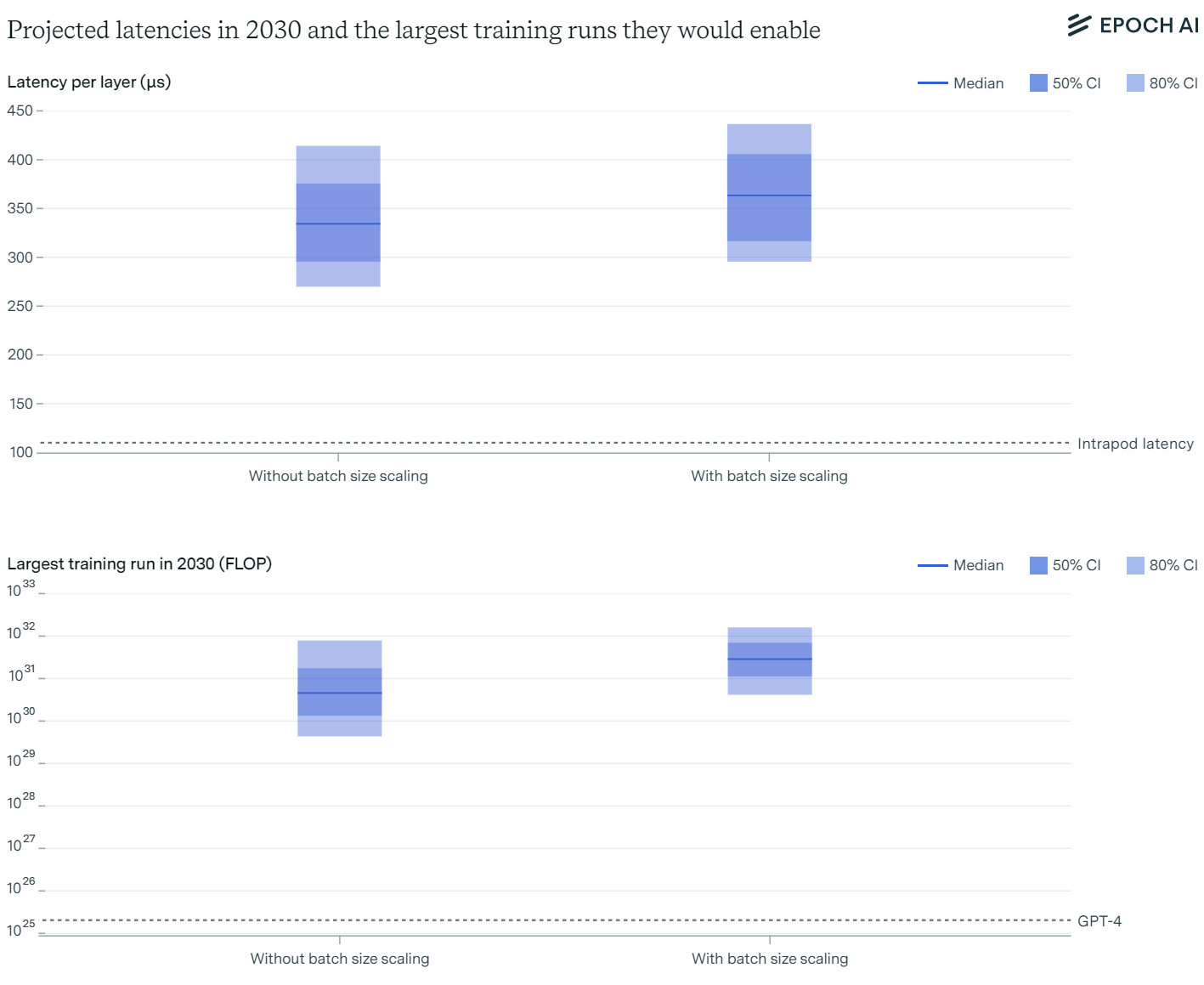
The latency wall refers to the fundamental speed limits in AI computations due to sequential processing requirements.
Latency Wall Given Intranode Latencies
Within a single node, latencies are minimal but increase with model size. By considering batch sizes and model parameters, we estimate that training runs up to 6×10316 \times 10^{31}6×1031 FLOP are feasible before hitting latency constraints.
Latency Wall Given Latencies Between Nodes
When considering internode communication, latencies increase due to factors like network topology. However, improvements in network design and communication protocols can mitigate these latencies. Scaling beyond 1×10321 \times 10^{32}1×1032 FLOP may require innovative solutions, such as new network topologies or adjustments in batch size scaling.
How Can These Latencies Be Reduced?
Potential strategies to reduce latency include adopting mesh topologies, increasing GPUs per node and developing more efficient communication protocols. Adjusting batch sizes and the number of layers in models may also help push back the latency wall.
What Constraint Is the Most Limiting?
Among the constraints analyzed, power availability and chip manufacturing capacity are the most immediate bottlenecks. Power may be more malleable due to the potential for expanding energy infrastructure, while chip production faces significant challenges in scaling advanced packaging and memory capacity.
Data scarcity presents substantial uncertainty, especially regarding the utility of multimodal data and the feasibility of synthetic data. The latency wall is a more distant constraint but will become significant as models continue to scale.
Will Labs Attempt to Scale to These New Heights?
Whether AI labs will pursue scaling to the projected levels depends on economic factors and the potential return on investment. The continuous improvement in AI capabilities with increased scaling suggests that labs may find it worthwhile. Reports of significant investments, such as Microsoft's and OpenAI's rumored $100 billion data center project, indicate industry momentum toward larger-scale training runs.
The potential economic payoff from automating substantial portions of economic tasks is enormous. Investing trillions in AI development and infrastructure could be economically justified if AI can effectively substitute for human labor, potentially driving unprecedented economic growth.
Conclusion
Our analysis suggests that, based on current trends, training runs of up to 2e29 FLOP are feasible by 2030. This scaling is likely to continue unless constrained by significant bottlenecks in power supply, chip manufacturing, data availability or latency.
Power availability and chip manufacturing capacity are the most pressing constraints that need to be addressed to sustain scaling. Overcoming these challenges could lead to AI models with transformative capabilities, attracting massive investments and potentially becoming one of humanity's largest technological endeavors.
For the full report: https://epochai.org/blog/can-ai-scaling-continue-through-2030
Stay tuned to the AI Lab Series for more deep dives into the evolving world of artificial intelligence. Together, we'll explore the trends, challenges and innovations shaping our future.